
It’s an election year, so the news is full of articles about where candidates rank in national polls. These polls are considered accurate, but how can that be since the pollsters can’t possibly ask every voter in the country which candidate they like best? The pollsters use sampling methods to find a small group of people who are representative of the entire population.
In a statistical study, a sampling method is how we select members from the population to partake in the research. Sampling is a common practice because it’s seldom possible to collect data from every person within a group.
Sampling methods are used to select a representative group of the researcher’s “target population.” For political pollsters, the target population can include the entire population of a state or country, but more often researchers are trying to learn about a selected population, such as patients with a specific health condition or college graduates in a particular region.


Using the right sampling method is critical. The closer the sample group represents the target population, the more accurate the results will be. Before we dive into your choices for sampling methods, let’s cover some basics:
Sampling frame: This is the actual list of individuals or source material from which the sample will be drawn.
Sample size: This is determined by the size of the target population. Your target population will be larger if you’re focused on all New Yorkers who own dogs than if you’re focusing only on New Yorkers who own dalmations.
In general, the larger your sample size, the more confident you can be in the accuracy of your results. Using a sample size calculator helps you determine an adequate sample size.
Margin of error: This percentage tells you how much you can expect your survey results to reflect the views of an overall population. The lower, the better.
Types of sampling methods
There are probability sampling methods and non-probability sampling methods. Determining which one is right for your survey or research depends on what you’re planning to do with the results, as well other factors in your target population. We’ll detail the main types below.
Probability sampling methods
Probability sampling means that every member of the population has the same chance of being selected so that your results won’t end up skewed or biased. To produce results that are representative of an entire target population, use one of these four probability sampling techniques:
Simple random sample: A simple random sample is entirely based on chance so that every member and set of members has an equal chance of being included in the sample.
An example of a simple random sampling might be a teacher putting slips of paper with the names of every student in a hat and drawing a predetermined number of slips without looking. For larger populations, technology like random number generators can assist researchers seeking a genuinely random sample selected by chance.
This sampling method yields a representative sample because it excludes bias in the selection process.
Systematic sample: This is a variation of simple random sampling. Every member of the population is assigned a number, but instead of using a random number generator, individuals are selected at regular intervals.
For example, a school principal assigns a number to every name on an alphabetized list of all of the students in school. After selecting a random starting point (let’s say number 5), the principal could then select every tenth student — 5, 15, 25, etc. — until there’s a random sample of 100 students.
Researchers need to be aware of hidden or unintended patterns in the list that unintentionally result in a sample that isn’t entirely randomized. If the principal’s alphabetized list of students was also organized by grade, starting with freshman, the resulting sample could skew toward the younger students.
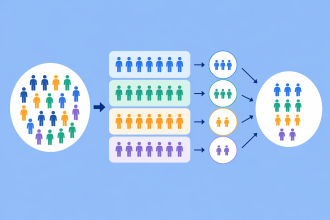
Cluster sample: Cluster sampling works by dividing the population into subgroups, each with characteristics similar to the whole sample. Instead of selecting individuals from the entire population, you randomly select individuals from the subgroups.
This method is ideal for large populations, but there may be differences in your subgroups that make it unclear if your clusters represent your entire target population.
Let’s say you own a chain of 100 restaurants and want to survey your employees. Instead of surveying every employee, you use the cluster sampling to collect data from five restaurants that have a similar number of employees.
Stratified sample: This involves splitting the population into groups and randomly selecting some members from each group to serve as the sample. You can calculate how many people should be sampled from each subgroup based on the proportions of the population.
Non-probability sampling methods
Non-probability sampling is easier and cheaper to produce than probability sampling, but because it isn’t based on random criteria, you can’t use the sample to make valid statistical inferences for testing a hypothesis.
However, these methods are valid and useful for qualitative research, such as developing a deeper understanding of a less-researched population.
Convenience sample: This involves selecting a sample that’s readily available in a non-random way. An example might be a retailer who offers a discount to shoppers in exchange for completing a questionnaire. The sample is comprised only of those shoppers who decide to participate, but their answers can nonetheless be useful to the owner of the store.
Voluntary response sample: A common example is a public online survey, in which the researchers collect data from those who volunteer to participate. The researcher doesn’t choose participants, so these are always somewhat biased. The people likeliest to respond voluntarily are those with strong feelings regarding the survey subject, so their opinions may not be representative of your whole population.

































Send Comment:
1 Comment:
October 29, 2021
In the sampling methods it is mostly our own ideas, as in the writer is coming with how they will want to conduct their research but when it comes to publishing research papers journals can be very specific about similarity percentages so would you advice scanning each of our research sections, in this case ti would be the sampling chapter, for plagiarism with something like plagiarismcheckerx.com, grammarly, quetext etc. or do you recommend saving those scans for more substantive sections?